

As a Solutions Architect and after all the years helping my clients select the right architectures for their use cases or requirements I have come up with a certain realization. My primary job is to identify and present a list of trade-offs for anything that I build (for my clients) and make sure I help them select the best option. If you have heard the expression – ”You can’t have your cake and eat it (too)”, this blog is going to put you in a similar dilemma. I’ll describe four distributed Kubernetes (OpenShift) Architectures and their trade-offs to help you decide which one is right for you. Spoiler alert, there is no single option that is better than the rest.
Let’s start with some assumptions.
- My private cloud of choice is OpenStack. Not all of the considerations will translate to other datacenter technologies or public clouds
- Distribution of the resources has its limitations. As a matter of fact etcd that is used by Kubernetes has a single digit to low double digit latency requirement. Other words, in order for us to consider stretching Kubernetes across availability zones, we need to ensure those are not too far apart geographically.
- Some of the characteristics might not be available in the upstream versions of the components used in this analysis and at least have not been tested nor verified.
Here is the overall architecture:
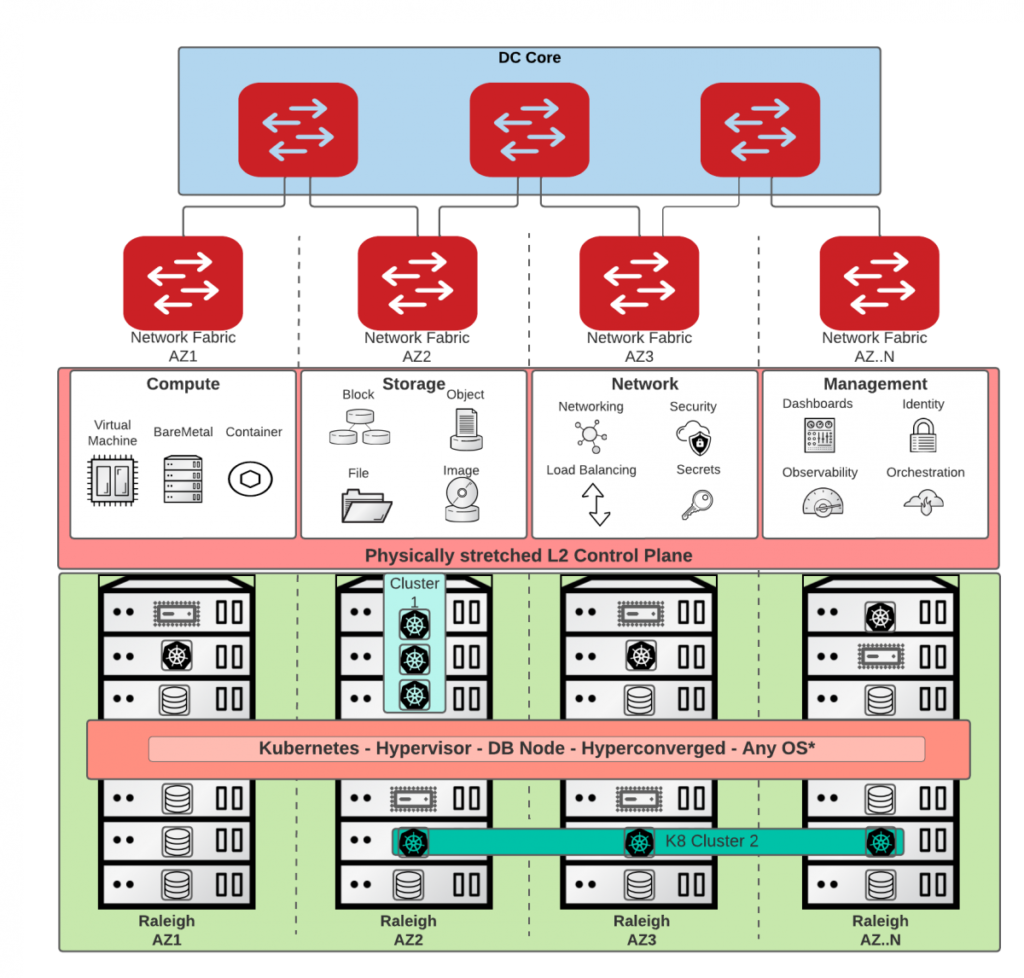
Characteristics:
- Multiple availability Zones
- Same geographical location
- L2 stretched Openstack control plane (for now)
- Kubernetes cluster per AZ or stretched across AZs
- Routed Networking between AZs
- Availability of all services across 3 AZs (any one AZ can be killed at any time without disruption of the services)
Now, let me show you four viable openshift deployment architectures that can stretch over multiple availability zones (to enhance SLAs). Especially the first 2 are my strong recommendation to consider, since they use most automation for its lifecycle.
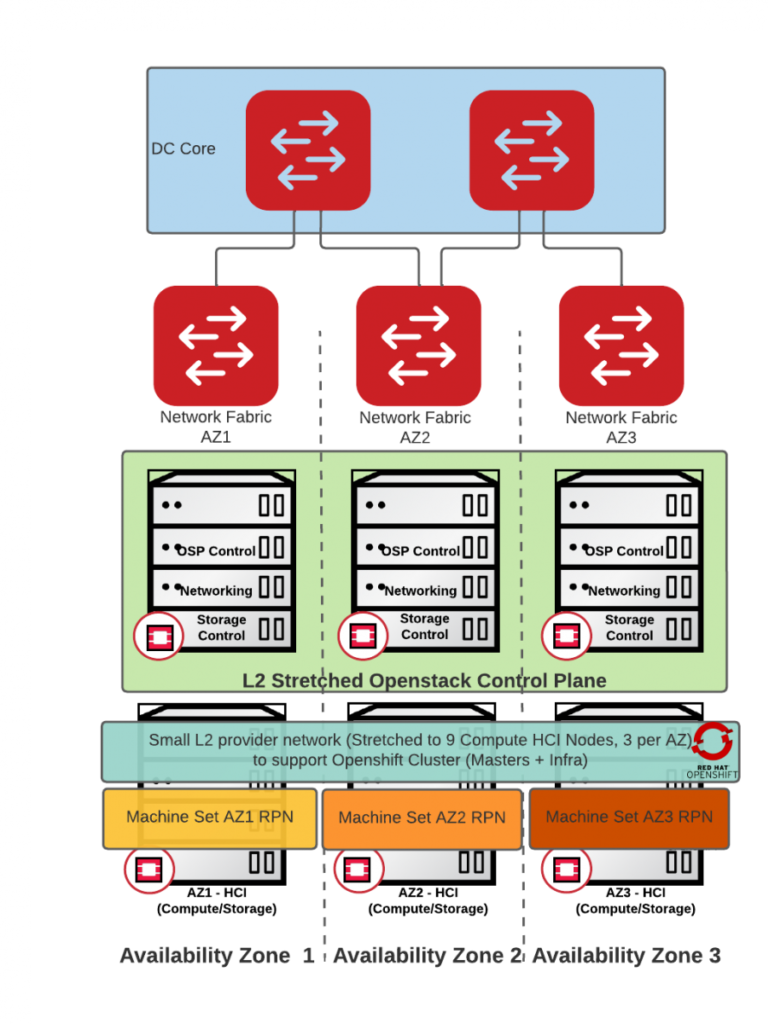
Architecture #1 – IPI – RPN with small stretched L2 for OCP control
Implementation:
Day 1:
Install minimal OpenShift (Kubernetes) using automation (IPI) over stretched L2 Provider network (1 master and 1 worker per AZ).
Day2:
Create Dedicated MachineSets per AZ for new workers. Scale-out as needed
Pros:
- Full use of Openshift (Kubernetes) installer automation
- Worker nodes use Routed Provided Networks (RPN) for workload high performance & availability
- Stretched network can be done one-per-cluster or combined as desired
Cons:
- Uses Administrator managed VLAN based networks (operational overhead)
- Openshift control plane availability dependant on high availability of the stretched network’s gateways
- Openshift Master/Infra nodes do not use RPNs
- For multiple clusters a potential need for additional stretched L2 due to VRRP collision
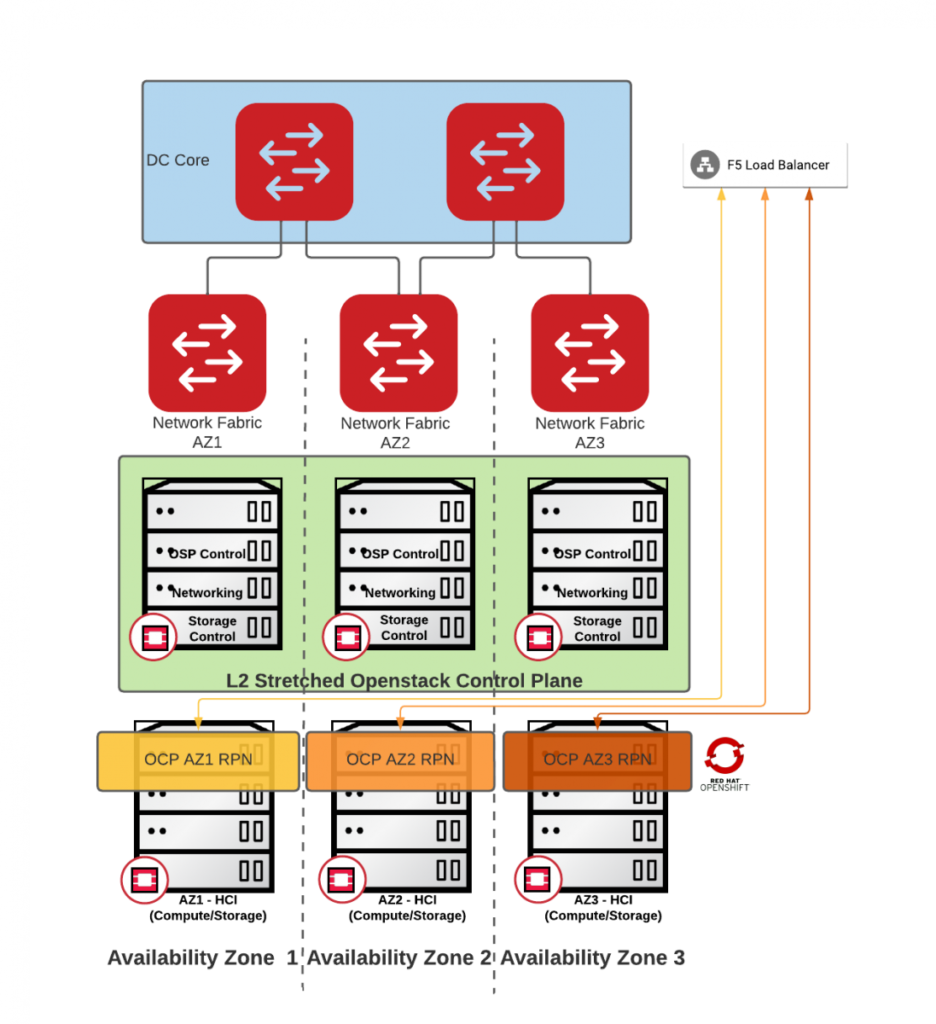
Architecture #2 – IPI – Overlay network with no-DVR on FIPs
Implementation:
Day 1:
Install fully blown OpenShift (Kubernetes) using automation (IPI) over an overlay tenant network. The ingress and API handles by a floating IP with disabled DVR
Day2:
No action required. Scale-out as needed
Pros:
- Simplest architecture
- Only 3 Routable IPs required (min) per Openshift cluster
- optional day 2 operation to scale out per AZ workers
- No admin work required with every new cluster (no operational overhead)
Cons:
- SNAT for workers without a Floating IP
- No external access to most workers
- Performance can be affected by double encapsulation

Architecture #3 – UPI – RPN with external load balancer for control plane
Implementation:
Day 1:
Install fully blown OpenShift (Kubernetes) using manual configuration (UPI) over Routed Provider Networks with 3rd party load balancer
Day2:
Scaling out can require additional manual configuration
Pros:
- No stretched L2 Provider network required
- OCP Master/Infra & Worker nodes use RPNs for workload performance & availability
- Easy integration with some enterprise load balancers (example – F5 operator available if desired)
Cons:
- Significant lifecycle overhead
- Inability to create new clusters with automation
- 3rd party needs to handle infrastructure load balancing
- Load balancing configuration is manual (unless automation is created)
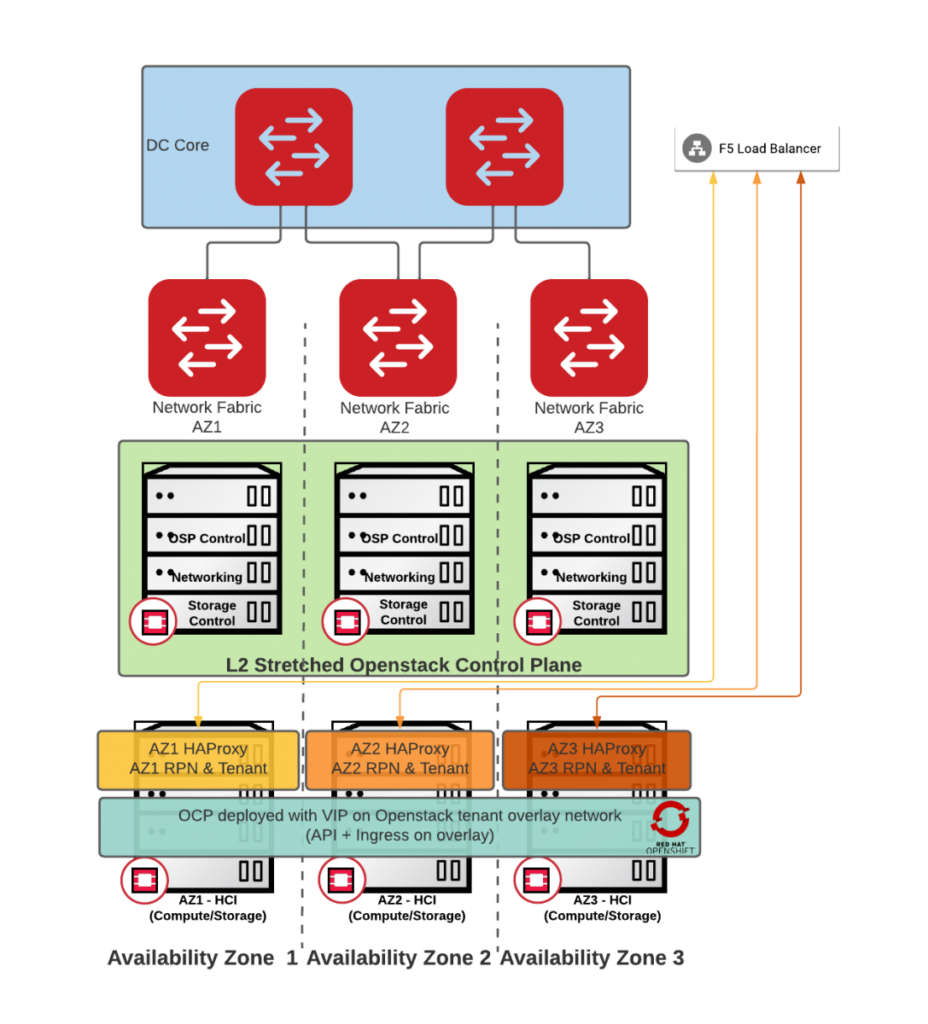
Architecture #4 – Overlay with 3rd party HAProxy controllers
Implementation:
Day 1:
Openshift installation is partially automated (IPI) with a load balancing component deployed manually and attached to appropriate overlay and provider networks
Day2:
After the most laborious Day1+, the scale-out should have the least friction, but operational overhead of HAProxy VMs is there.
Pros:
- No stretched L2 Provider network Requirement
- DVR available for high availability and performance
Cons:
- Significant lifecycle overhead
- 3rd party integration (HAProxy), outside of vendor support
- Worker nodes use SNAT
- No external access to OCP nodes
- Would require testing
In summary these are 4 viable architectures that could be used for stretching Kubernetes across multiple availability zones in distributed architecture.
You have been warned, there is no one architecture to rule them all. The most tradeoffs are around operational overhead, performance and availability, but today you can’t have it all.
There is however light in a tunnel. The future architectures might be able to take advantage of BGP to automatically distribute OpenShift nodes over RPNs in multiple AZs Day1, without a need of external load balancer. In such architecture the operational overhead could be reduced without sacrificing performance or availability. I’ll leave this topic for another time (when the feature is actually implemented) and another blog post.